【初心者向け】画像生成AIのStable Diffusion(WebUI)のインストール・使い方・日本語化・拡張機能・おすすめグラフィックボードについて解説

この記事はなんかよくわからんけどとりあえず画像生成AI使ってみたいぞ!という人に向けての記事です。
必要最小限の内容しかないので、あまり迷わず導入できると思います。
超初心者ガイド的な感じで使ってもらえると幸いです。
調べると多くの方が導入方法を記事にされていますが、この記事では「あんまりPC詳しくねえな~」という人にフォーカスしていきますので、中級者以上の方は他の記事をお読みください!
インストール・使い方・日本語化については冒頭で説明し、Stable DiffusionやWebUI概要については後半の方にまとめておきます。
準備するもの
PC
そこそこスペックの良いパソコン。CPU、メモリはそれなりのものであれば何でもよいが、グラフィックボード(GPU)にはこだわった方が良い。
具体的にはVRAMが12GB以上のモデル(8GBでも動きますが、高解像度や拡張機能のことを考えるとね…)
これからPC買う人は、VRAMというグラフィックボードのメモリがとにかく大きい物を買うほうが幸せになれる。
筆者のパソコンはCPU,メモリはそれなりの物を積んでいるが、グラボが1660ti(VRAM6GB)なので結構辛い。
一応念のため書いておくがイラス生成時にはガンガン処理させるのでノートパソコンよりもデスクトップパソコン推奨。
オススメグラフィックボードについては後半に書いておきますが、とりあえずNVIDIA GeForce RTX3060のVRAMが12GBがあればなんとかなると思います。
インストールが必要なソフトウェア
それぞれなにかは細かく説明しないので、とりあえずインストールしてくださいな。
Python
WebUIを動かすために必要なミドルウェア。
下記リンクにクリックしてPythonをダウンロード。OSに合わせたバージョンをダウロードしてください。

あとはダイアログに沿ってインストールしていくだけ。基本的に「Installnow」でOK。
Git
これも必要な奴。拡張機能をインストールしたりするのに必須。

ダイアログは全部「next」でOK。
CUDA
グラフィックボード関係のソフト。

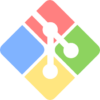
Windowsのバージョンによって落とすべきものが別なので注意。
WebUIの初期設定
WebUIのダウンロード
まずはWebUIをダウンロードします。
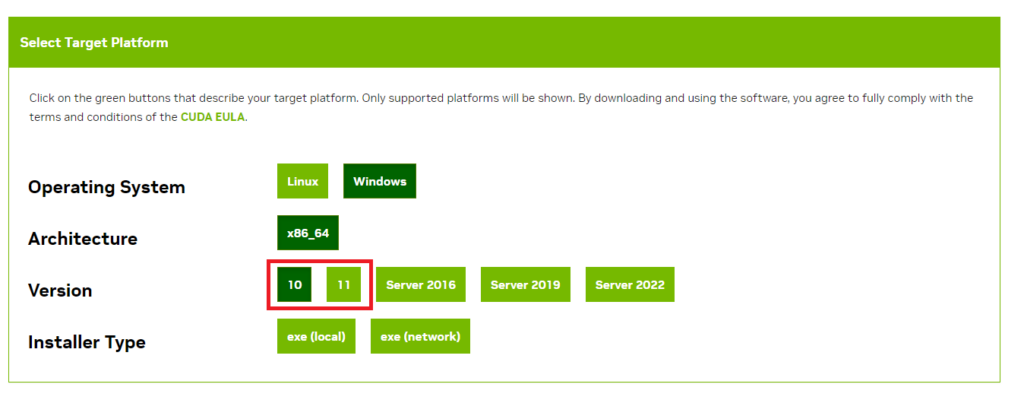
下記URLから「sd.webui.zip」をダウンロードしてください。

その後任意の場所にzipファイルを解凍してください。
モデルのダウンロード
(2023/3/5追記)おすすめモデル一覧を作りましたのでこちらもどうぞ!

追記終わり。
イラスト生成するには学習モデルが必要になります。
どのモデルがどうとかの説明は長くなるので省きますが、これを読んでいる人は美少女のイラストを生成したいであろうと断定し、一番設定が楽なAnythingV4.0のリンクを貼っておきます。

「anything-v4.0.ckpt」と「anything-v4.0.vae.pt」をダウンロードしてください。結構重たいので時間かかります。
モデルの格納
「anything-v4.0.ckpt」を解凍したWebUIの「Stable-diffusion」フォルダに移行します。
格納先は「sd.webui」→「webui」→「models」→「Stable-diffusion」になっているとおもいます。
その後「anything-v4.0.vae.pt」をWebUIの「VAE」フォルダに移行します。
格納先は「sd.webui」→「webui」→「models」→「VAE」になっているとおもいます。
WebUI起動
「sd.webui」のフォルダに「run」というbatファイルがあるのですが、それをクリックしてください。
しばらく経つと黒い画面の中に、http:// 123.456.789みたいなIPアドレスが出てくると思いますので、それをコピーしてブラウザで開いたら完了です。
エラーが出ている場合は、一度「update」のbatファイルを押して更新してみてください。
WebUIの日本語化
起動した画面の中に「Extensions」というボタンがあるかと思いますが、それ押し、「Localization」のチャックボックスを外し(”外し”ですよ!)、「Lordform」というオレンジのボタンを押します。
その後、「ja_JP Localization」を「Install」します。インストール完了後「Setting」の中にある「User InterFace」の「Localization」のプルダウンを開き、「ja_JP」を選択します。
上側にある保存ボタン的なのを押し、一度ブラウザタブを閉じ、「run」のウィンドウも閉じた後に、「run」を押してブラウザから開いたら日本語になっています!
WebUIでの画像生成
あとは使用するモデル、調整、プロンプト(描写して欲しい物)とネガティブプロンプト(描写してほしくないもの)、モデルからどんなふうに引っ張ってきて欲しいかなどを決定して生成したら完了です。
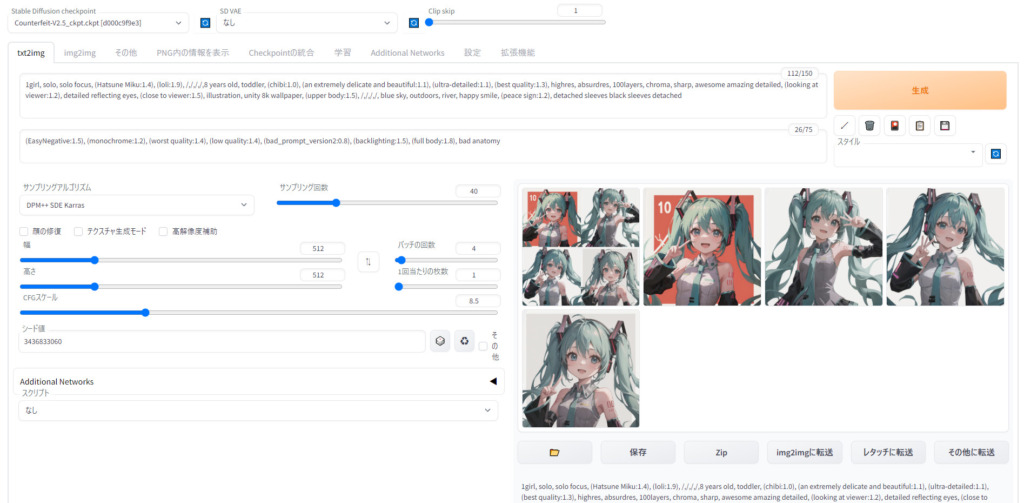
プロンプトの探し方
とはいえ自分で1から書くのは流石に大変だと思いますので、まずは公開されているプロンプトをベースに生成してみることをおススメします。
下記のようなサイトでは日夜様々な人がAI絵を生成してプロンプトごと投稿していますのでかなり参考になるかなと思います。

各種設定
サンプリングアルゴリズムについて
とりあえず公開している人のプロンプトと同じサンプリングアルゴリズムを使うのが良いと思いますが、自分は大体「DPM++SDE Karras」を使っています。
サンプリング回数について
サンプリング回数は20で良いですが、上手くいかない場合は増やします。
幅・高さ
グラフィックボードの性能が良ければ大きくできますが、そうではない人は512*512で我慢しましょう…。
バッチの回数
これは同じプロンプトで何回生成するかという数字です。当たり前ですが数を増やせば増やすほど生成時間が伸びますので、まずは1回で生成してみてどんなふうになるかを試してみるのが良いと思います。
1回あたりの枚数
1回のバッチで何枚生成するかという数字です。気に入ったプロンプトが出来たら、バッチと枚数をガンガン増やしていい感じの絵を探してみることをオススメします。
シード値
乱数です。基本はランダムの「-1」で良いですが、もし公開されている絵に近づけたいということであれば、公開されているシード値を選択すると良いかと思います。
おすすめ拡張機能
LoRA
特別な学習をさせた追加モデルみたいなやつです。特定のキャラを生成したいという人にはお勧めです。
これについてはまた別途記事を書きます。
Controlnet
棒人間を使用し、意図したポーズで画像を生成できるツールです。
これについても長くなるので別途記事を書きます。
一旦まとめ
この後も概要やおすすめグラフィックボードなどを書いていこうと思いますが、とりあえずインストールと生成までは出来たかな~と思います。
ダメそうでしたら試行錯誤してみてください…。なんかこの界隈情報の更新が早くてどんどん変わっていくので追いつくのも大変…。
Stable Diffusionとは
Stable Diffusionとは入力したテキストをもとに、AIが画像生成してくれるオープンソースのツールです。
ディープラーニングって昔流行ったと思うんですが、要するにそれの1モデルです。
テキストから画像を作成、画像から別の画像を作成が可能です。
WebUI(AUTOMATIC1111)とは
AUTOMATIC1111という方が開発されたStable Diffusionをブラウザ上で動かすためのUI(インターフェース)です。
本来Stable Diffusionの設定などは結構めんどいのですが、それらを簡単に設定してくれます。
また、様々な拡張機能との互換や日本語化などもできるので、とりあえず使ってみたい人には超オススメします。
おすすめグラフィックボード
イラスト生成や拡張機能を試していると気づく方もいると思いますが、この作業、めっちゃグラフィックボードの性能に左右されます。
なのでメモリエラーなどが頻出する人はグラフィックボードを買い替えることをオススメします。
コスパ重視ならNVIDIA GeForce RTX3060(12GB)
コスパを考えるならNVIDIA GeForce RTX3060のVRAMが12GBのモデルがオススメ!
画像生成はとにかくVRAM容量が大事!
性能重視ならNVIDIA GeForce RTX4090(24GB)
これがあればよほど技術が進歩しない限り最前線で戦えるのでオススメなんだけど、流石にちょっと高い…。
まとめ(2回目)
というわけでStable DiffusionをWebUIで動かす方法についてまとめていきました。
かなり楽しいのでぜひ一度お試しください~~~!
 ここまで読んでくださりありがとうございました。 ここまで読んでくださりありがとうございました。Twitterもやっていますので、お気軽にフォローしてください! (Twitterのフォローはこのリンクからどうぞ!) |